文字情報のデジタル表現
1.はじめに
さて、以上で文字や数値などの情報を2進法で表現するための準備が整いました。それでは、いよいよコンピュータの中で実際に使われている表現方法を学んでいきましょう。まず初めに、文字情報をコンピュータ上で表現する原理について学びます。
2.文字のデジタル表現
2−1 コード化
コンピュータで情報を表す第一歩は、様々な記号の中からコンピュータで表すべき記号を選択することです。例えば、漢字ならば使用頻度の高いものを選択する必要があります。次に、選択した記号をどのようなビット列に対応づけてコード化(符号化:encoding)するかを決めなければなりません。例えば、00が晴れ、01が曇り、10が雨、11が雪という対応づけをすることも、立派なコード化です。コード化された記号全体をコード系(character
encoding system)と呼び、通常は表の形でまとめられます。この表のことを、コード表(character
encoding table)といいます。
文字のコード化は、文字記号の少ないアルファベット圏では比較的容易ですが、漢字圏のように多数の文字があるところでは様々な問題があり、困難です。どの文字を採用するかを考えることも大変ですし、採用した文字とビット列の対応づけも面倒な作業になります。加えて、後で文字を追加するときには、先に作られたコード系といかに整合性を保つかといった多くの作業をこなさなければなりません。
2−2 コード化の規約
さて、実際にコード化はどのように行われているのでしょうか。かってなコード化が行われれば、ソフト間のデータのやりとりや通信に混乱が起こることは容易に想像がつきます。電話回線や通信回線を使用して文字データを送受信する場合にはお互いに文字の構成フォーマットを決めておかないと送信した文字情報を受信した文字情報とが一致せずに意志を伝えることができません。ですから、コード化の作業は、関係者や関係諸団体が集まって議論をしながら行われています。
コンピュータは英語圏のアメリカで誕生したので、まず英語のアルファベットのコード系がつくられました。今日の社会では英語は事実上の国際語として機能しているため、このコード系はすべてのコンピュータ社会で使えるようになっています。しかし、コンピュータが広く日常的に使われるようになると、英語圏以外の国は自国の言語に応じたコード系を作るようになりました。それらのコード系はその言語圏でのみ利用することを前提として作られたので、インターネットのように国際的なコンピュータネットワークが普及しはじめると様々な問題が表面化してきました。特に、文字数の少ないアルファベット圏と漢字のような文字数の多い言語圏との間では、記号に割り当てるビット数の違いなど、大きな問題が生じたのです。
現在、日本で使われている代表的なコード系としては、iso-2022-jp、シフトJIS、EUC-JP、Unicode(UTF-8, UTF-16) などがあります。
3. 文字コード化の実際
ここでは、実際のコード化がどのように行われているかについて見ていきます。ただし、漢字は個数が多く、コード表の全貌を見渡すことが大変ですので、英文字のコード表について見ていきます。
3−1 7ビットコード系
図1はISO(国際標準化機構:International Organization for Standardization)が定めたISO7ビットコード表と呼ばれるものです(注1)。
注1 ISOの規格は、全ての国の詳細な規格を定めたものではなく、各国で共通に使われる部分を定めたものだといえます。具体的な規格は、各国の標準化団体(日本ではJIS)が決めています。表に示したISOとASCIIを比べるとこれがわかります。なお、ISO,ANSI,JISは文字コードに限らず、あらゆる工業製品の規格に関わっています。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | NUL | TC7 | SP | 0 | ★ | P | ★ | p |
| 1 | TC1 | DC1 | ! | 1 | A | Q | a | q |
| 2 | TC2 | DC2 | ” | 2 | B | R | b | r |
| 3 | TC3 | DC3 | ★ | 3 | C | S | c | s |
| 4 | TC4 | DC4 | ★ | 4 | D | T | d | t |
| 5 | TC5 | TC8 | % | 5 | E | U | e | u |
| 6 | TC6 | TC9 | & | 6 | F | V | f | v |
| 7 | BEL | TC10 | ’ | 7 | G | W | g | w |
| 8 | FE0 | CAN | ( | 8 | H | X | h | x |
| 9 | FE1 | EM | ) | 9 | I | Y | i | y |
| A | FE2 | SUB | * | : | J | Z | j | z |
| B | FE3 | ESC | + | ; | K | ★ | k | ★ |
| C | FE4 | IS4 | , | < | L | ★ | l | ★ |
| D | FE5 | IS3 | − | = | M | ★ | m | ★ |
| E | SO | IS2 | . | > | N | ★ | n | ★ |
| F | SI | IS1 | / | ? | O | _ | o | DEL |
図1 ISO7ビットコード表
さて、図1のISO7ビットコード表とは、その名のとおり7ビット、すなわち128通りのビット列一つ一つに記号を割り当てたものです。上側の0〜7の16進数は上位3ビット、左がわの0〜Fの16進数は下位4ビットを表しています。実際に表を見てみると、例えば、大文字のAは16進数では41、すなわち2進数では1001000というビット列に対応しています。すなわち、この7ビットコード系に基づいた場合、コンピュータにとって大文字のAは1001000というビット列として扱われます。
また、表を見ると、FE5(0Dのとこ)やESC(1Bのとこ)、DEL(7Fのとこ)など、見慣れない文字列があります。これらは文字コードではなく、コンピュータに特定の機能を実行させる役割が割り当てられた、いわゆる機能コードです。例えば、NL(new
line)、CR(carriage return)は、多くのコンピュータで「このコードがきたら行をかえるのだぞ」(改行)という意味で使われています。なお、2列の0行に「SP(空白)」とありますが、これはスペースを表しています。また、★が入っているマスは各国の標準化団体が独自に決めることができます。また、次の図2は世界中で通用する事実上の標準であるASCII7ビットコード表です。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | NUL | DEL | SP | 0 | @ | P | ` | p |
| 1 | SOH | DC1 | ! | 1 | A | Q | a | q |
| 2 | STX | DC2 | ” | 2 | B | R | b | r |
| 3 | ETX | DC3 | # | 3 | C | S | c | s |
| 4 | EOT | DC4 | $ | 4 | D | T | d | t |
| 5 | ENQ | NAK | % | 5 | E | U | e | u |
| 6 | ACK | SYN | & | 6 | F | V | f | v |
| 7 | BEL | ETB | ’ | 7 | G | W | g | w |
| 8 | BS | CAN | ( | 8 | H | X | h | x |
| 9 | HT | EM | ) | 9 | I | Y | i | y |
| A | LF | SUB | * | : | J | Z | j | z |
| B | VT | ESC | + | ; | K | [ | k | { |
| C | FF | FS | , | < | L | \ | l | | |
| D | CR | GS | − | = | M | ] | m | } |
| E | SO | RS | . | > | N | ^ | n | 〜 |
| F | SI | US | / | ? | O | _ | o | DEL |
図2 ASCII7ビットコード表
3−2 半角カタカナを表すには?―JIS7ビットコード系
コンピュータが普及するにつれ、コンピュータでの日本語処理も求められるようになりました。そこで、ASCII7ビットコード表の機能コード以外の部分をそっくりカタカナに置き換えてしまう方法が考えられ、図3に示した7ビットJIS X 0201の原型(JIS C 6220)が1967年に制定されたのです。この規格のおかげで、何とか日本語をコンピュータで使うことができるようになったのですが、このコード系では英文字はおろか、数字さえも利用できません。そこで、特定の機能コードをASCIIと7ビットJISの切り替え記号に使おうという考えが生まれました。7ビット、すなわち128通りのビットパタンで英文字、数字、カタカナを利用するには、このような工夫が必要だったのです。
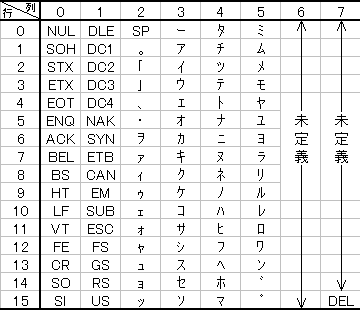
図3 JIS C 6220 コード表(列と行は10進表記に改めている)
3−3 8ビットコード系
カタカナと英文字を共存させるには、どのようにしたらよいでしょうか?これは、7ビットに1ビット加えた8ビットのコード系を作ることによって解決されました。8ビット、即ち256通りのパターンを利用するのです。その際、8ビットへの拡張は7ビットコードのASCIIをそのまま含む形で行うのが合理的です。このようにして作られたのが、図4に示した「8ビットJISX0201」というコード系です。当然、このコード系は日本でしか通用しません。
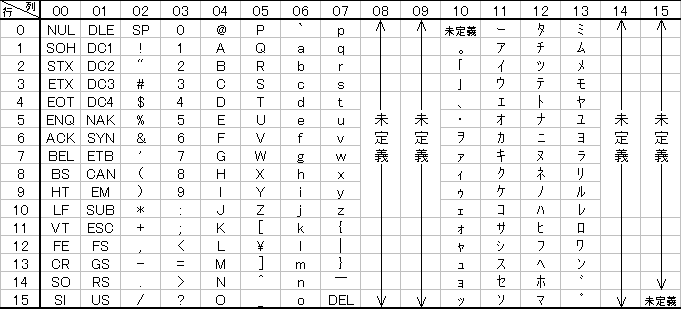
図4 JIS X 0201 コード表(列と行は10進表記に改めている)
表中、未定義という部分はJISでは規定されていない部分で、ワープロメーカーなどが独自に文字や記号を割り当てている場合があります。このようなJIS規格以外の記号や文字を外字と呼んでいます。
3−4 16ビットコード系
高機能なコンピュータが低価格で手に入るようになり、ますますコンピュータが日常的になってくると、日本語処理でも本格的な漢字の利用が始まりました。漢字の文字数は数万にのぼるため、現状ではその一部のコード化が行われているにすぎませんが、それでも実用的に漢字を扱うには8ビット=256パタンではとても足りません。そこで、漢字のコード化は16ビット=2バイト65536パタンで処理されることになりました。広く普及しているJISX0208で使える漢字の種類は、使用頻度の高いものを集めたJIS第一水準2965文字とそのほかのJIS第二水準3388文字のあわせてたったの6353文字です。これらの漢字を取り扱う規格としては、JISコード、シフトJISコード、日本語EUCコードの3種類がよく使われています。
また、コンピュータが世界的に普及するに伴い、様々な言語の各種アルファベットと漢字などの表意文字を統一的に扱おうという提案がなされており、ISOもこれを国際規格として採択しました。この規格はユニコード(Unicode)と呼ばれ、一部の例外を除き16ビットで全ての文字を取り扱おうとしています。しかし、文字は各国、各民族に固有の文化が関係してくるため、現状では全ての言語で使われる文字を統一的にもれなくコード化することは難しく、様々な調整がはかられています。